Portfolio Details


Quantifying Differences in LLM and Human Feedback on Mental Health Related Surveys
- Category: Research, Large Language Model
- Collaborator: Phoebe Cheng, Yixian Gan, Catherine Ni, Xiaohan Zhao
- Date: Fall 2023
Description
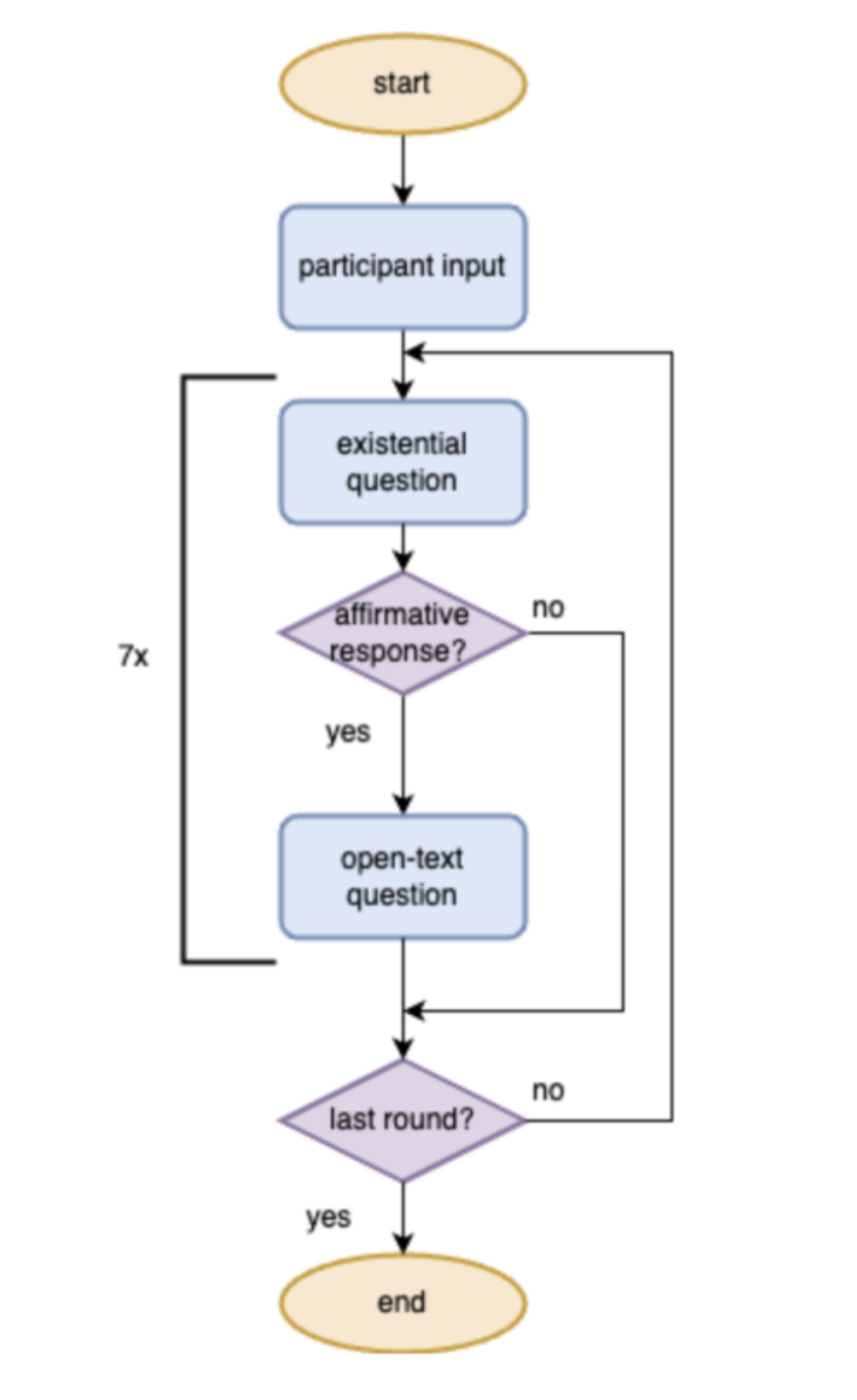
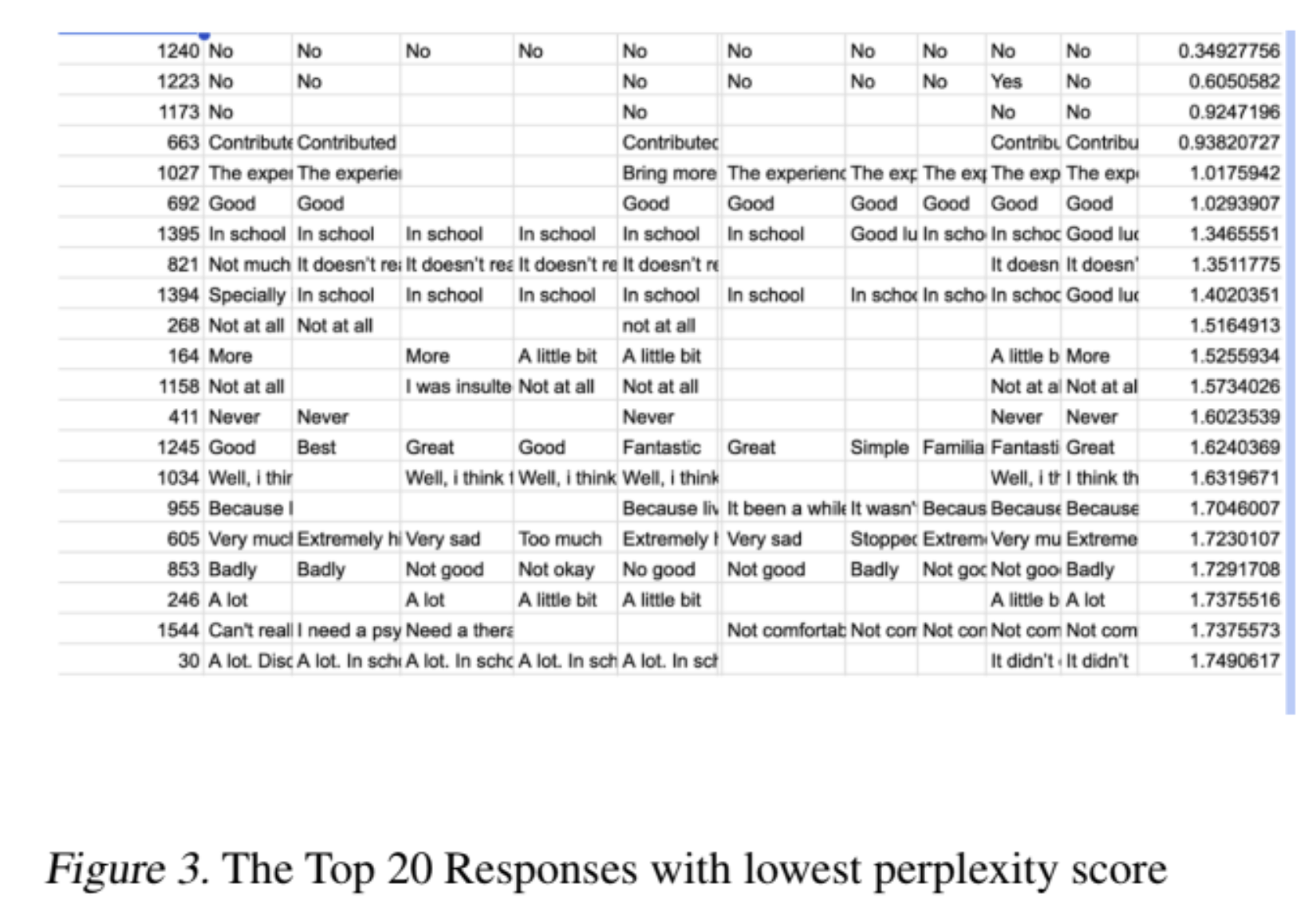
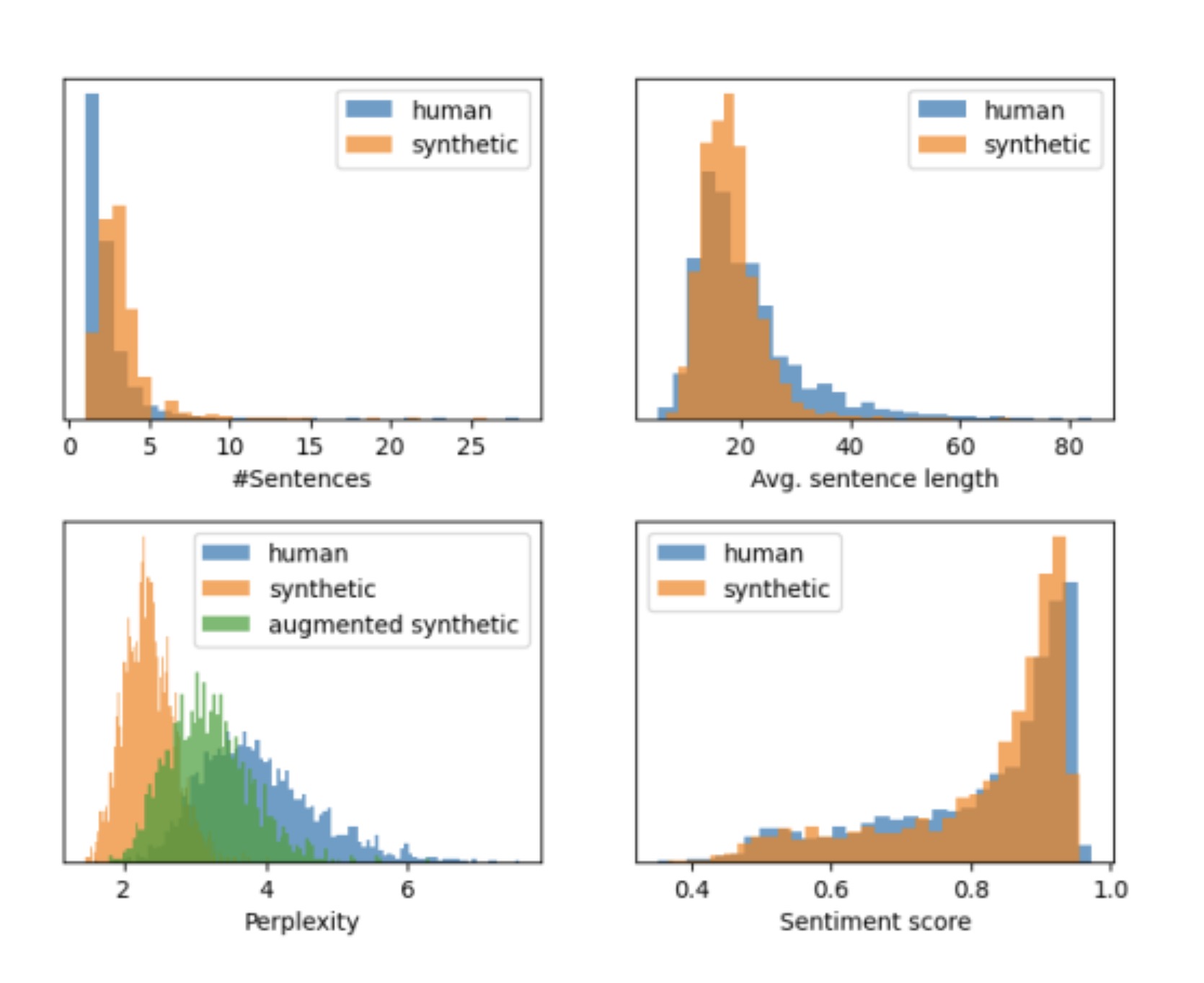
Our research pioneers the quantification of difference between LLM (large language model) and human-generated feedback on mental health surveys, addressing a gap in existing literature. Given the absence of existing dataset, we curated the first benchmark dataset for the detection of LLM-generated text in mental health domain. This involved generating fake responses using LLM and employing text augmentation techniques. On the detection front, we carefully examined the linguistic differences between LLM and human-generated text, uncovering valuable insights. We implemented models from different categories, i.e. tree-based models, transformer-based classifiers and in-content few-shot learning models, achieving impressive performance in detecting LLM responses. Our work carries important implications for ensuring data integrity in the mental health domain, offering crucial insights into the distinctive features of LLM-generated responses and contributing to the overall reliability of mental health survey data.